夏火松教授团队长期研究信息管理与知识管理,在知识管理与智慧管理、管理信息系统、电子商务、商务智能与大数据挖掘、物流管理工程、金融科技(FinTech)等领域的教学、科研及产业规划和管理咨询等社会服务工作中,不断取得好成绩,在结合我校特色纺织产业中的知识管理与智慧管理已经取得重要进展。
该团队最近在管理科学与工程技术期刊International Journal of Production Research(SCI 影响因子9.018,Q1,也是中科院分区中工程技术类TOP期刊)在线发表了一篇论文(Huosong Xia, Yuan Wang, Sajjad Jasimuddin, Justin Zuopeng Zhang & Andrew Thomas (2022) A big-data-driven matching model based on deep reinforcement learning for cotton blending, International Journal of Production Research, DOI: 10.1080/00207543.2022.2153942)。
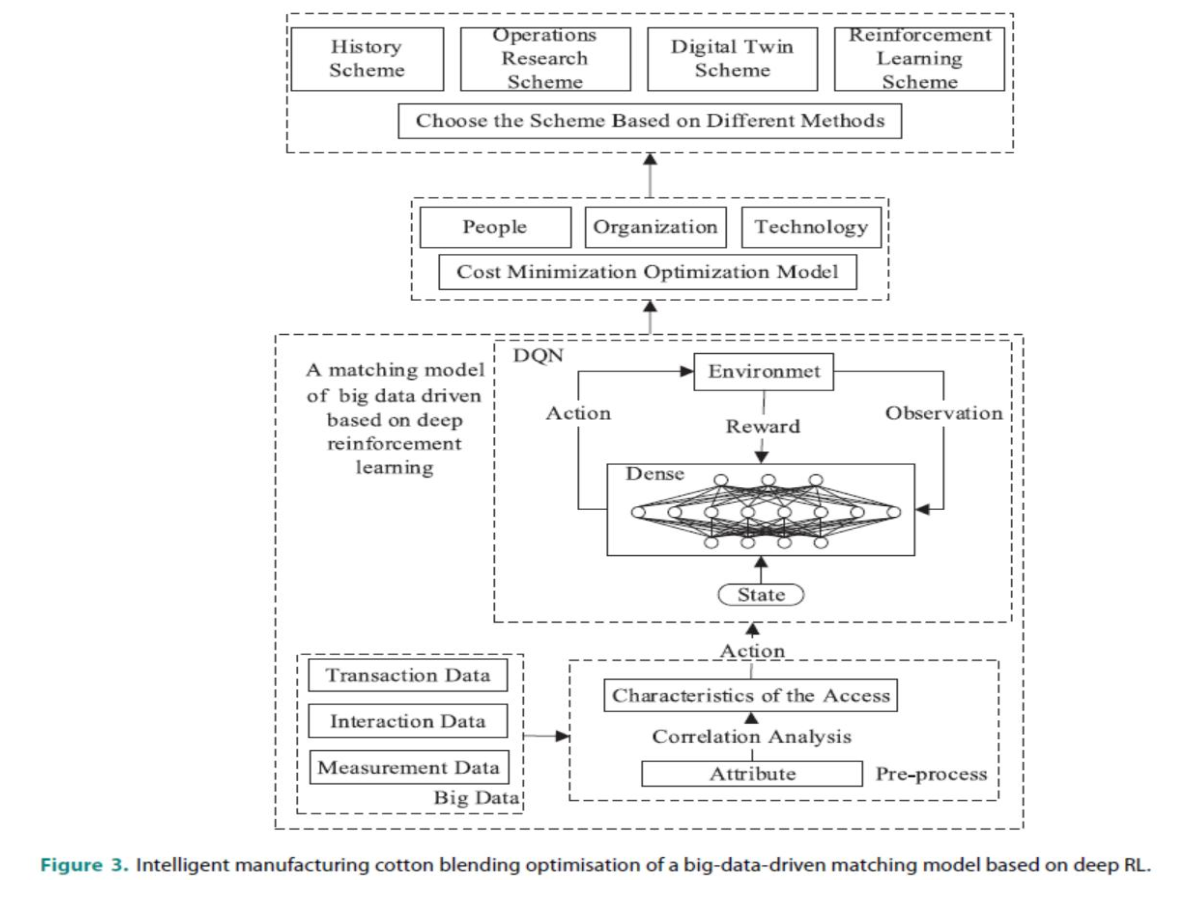
该论文主要解决我国棉纺织行业正处于数字化转型和升级的关键时期,如何应对劳动力成本上升和原材料价格大幅波动等压力和挑战时,在高保质量产品同时,解决智能制造中成本竞争优势的智能配棉问题。该研究课题是徐卫林院士提出与湖北武汉裕大华卫江总经理支持经费下开展了1年多的阶段研究成果。该研究从大数据和强化学习的角度,结合奖励机制和马尔可夫决策,设计了一个结合棉花匹配及交易数据、评论与新闻等交互数据和棉花期货指数等测量数据的奖励值,进行智能配棉中不同原料的组合开展的研究成果。该成果提出了基于大数据驱动与深度强化学习来解决智能配棉问题,构建了运用深度强化学习与大数据驱动的棉花匹配模型。设计了智能配棉策略,并使用强化学习的激励机制来迭代最优纱线匹配方案,以实现智能棉花匹配的目标。研究数值分析与模拟,以及利用收集的近2年手工配棉数据验证结果表明,利用大数据与深度强化学习模型建立的的大数据智能匹配模型效果较好。
成果研究三个问题如下:
QA1:如何在保证产品质量的前提下降低制造企业的成本?
QA2:如何利用大数据驱动匹配模型优化深度RL模型?
QA3:基于深度RL的大数据驱动匹配模型如何优化智能制造成本?
成果设计了基于大数据的奖励价值计算模型:
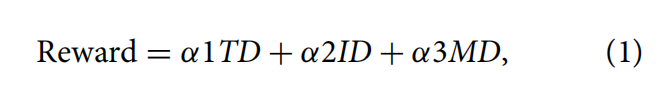
棉花混纺模型的奖励值如式(2)所示:
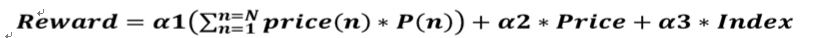
其中price表示棉花价格;N表示棉花的种类;P为各棉所占比例;Price表示纱线价格,Index表示棉花期货指数;a1、a2和a3褒示这三种数据在奖励中的比例。
数据集划分:
(a) 40支纱线。训练集= 31,验证集= 80 ,测试集= 46,总数= 45
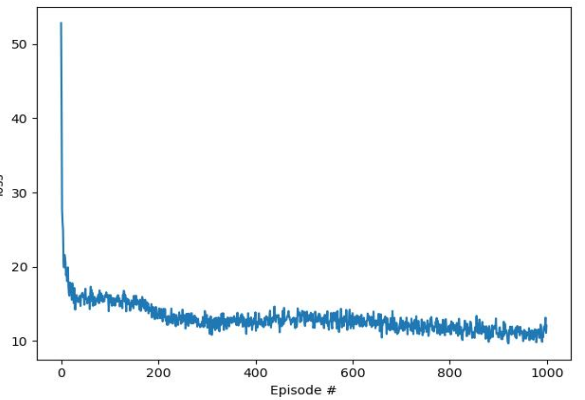
实验验证如下:RL中的Q神经网络模型,研究发现Q神经网络有很好的收敛性,如左图所示。通过梯度下降等方法更新网络的参数,使均方误差(MSE)损失越来越小直至收敛。模型的学习任务是改进预测值和实际值之间的平衡,提出的RL模型的结果也达到了最优解。
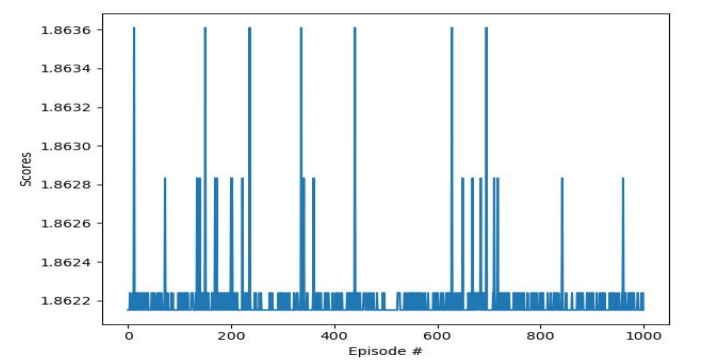
实例仿真与分析:以湖北省裕大华纺织企业的60根纱线为例进行混棉,寻找价格最低的混棉方案。论文使用相关分析来分析变量之间的相关性。最后,将调优前后的变量数量从7个减少到4个。原农司分为农八区棉、农六区棉、农七区棉统一为新疆棉花。
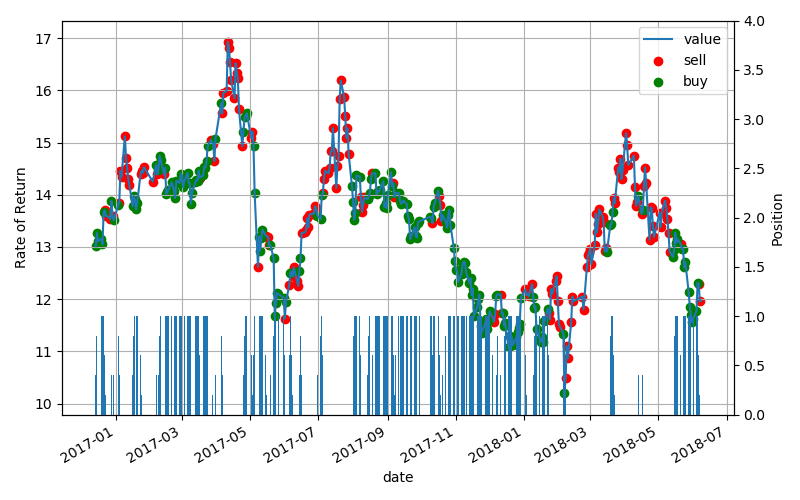
研究实验结果:对数据进行1000次迭代,实验结果如图所示。在每次试验结束时,给出一个最佳的棉花混纺方案。但在迭代的过程中,也会出现一些突出的突出现象。但在迭代过程中,每两支纱线所需的棉花成本在1.86225 - 1.86275之间,变化不大。说明在177种混棉方案中,以成本最低的混棉方案最为合适 60支纱线不改变质量可以找到的最好的结果。
论文将模型中棉混纺价格最高的方案与价格最低的方案进行了比较,结果如下表所示:
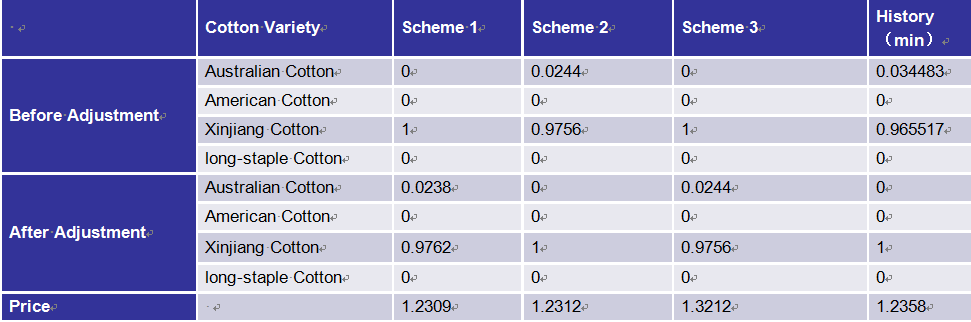
研究发现:本文从智能制造纺织企业出发,采用RL的方法,在不改变质量的前提下降低纱线成本,找到每根纱线成本最低的混棉方案(调整每种棉花的加入比例)。
(1)在保证质量的基础上,设计了一个大数据驱动的匹配模型来优化深度强化学习。大数据模型驱动的深度RL模型用于优化智能制造成本(Chen, He, and Shi 2014;Song and Li 2016);
(2)设计离线策略,构建记忆库和神经网络,利用RL的激励机制迭代优化配纱方案,实现智能配棉的目标;
(3)从大数据和RL的角度出发,结合交易数据、交互数据和测量数据,结合Reward机制和Markov决策(Arora and Doshi2021)。
附:
(Huosong Xia, Yuan Wang, Sajjad Jasimuddin, Justin Zuopeng Zhang & Andrew Thomas (2022) A big-data-driven matching model based on deep reinforcement learning for cotton blending, International Journal of Production Research, DOI: 10.1080/00207543.2022.2153942)